*1. 简述线程池?
没有线程池时,线程只能: 创建->初始化->使用->删除
线程池是一种线程使用模式,初始化时创建一定数量的线程,让他们时刻准备就绪等待新任务的到达,而任务执行结束之后再重新回来继续待命。
使用线程池的优势:
降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
2. 简述Runnable接口和Callable接口的区别?
Runnable自Java 1.0以来一直存在,但Callable仅在Java 1.5中引入,目的就是为了来处理Runnable不支持的用例。**Runnable** 接口不会返回结果或抛出检查异常,但是**Callable** 接口可以。所以,如果任务不需要返回结果或抛出异常推荐使用 Runnable 接口,这样代码看起来会更加简洁。
工具类 Executors 可以实现 Runnable 对象和 Callable 对象之间的相互转换。(Executors.callable(Runnable task)或 Executors.callable(Runnable task,Object resule))。
// Runnable.java
@FunctionalInterface
public interface Runnable {
/**
* 被线程执行,没有返回值也无法抛出异常
*/
public abstract void run();
}
// Callable.java
@FunctionalInterface
public interface Callable<V> {
/**
* 计算结果,或在无法这样做时抛出异常。
* @return 计算得出的结果
* @throws 如果无法计算结果,则抛出异常
*/
V call() throws Exception;
}
3. execute()方法和submit()方法的区别是什么?
execute和submit都属于线程池的方法,execute只能提交Runnable类型的任务,而submit既能提交Runnable类型任务也能提交Callable类型任务。
execute会直接抛出任务执行时的异常,submit会吃掉异常,可通过Future的get方法将任务执行时的异常重新抛出。
execute所属顶层接口是Executor,submit所属顶层接口是ExecutorService,实现类ThreadPoolExecutor重写了execute方法,抽象类AbstractExecutorService重写了submit方法。
**execute()**方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;
**submit()方法用于提交需要返回值的任务。线程池会返回一个Future类型的对象,通过这个Future**对象可以判断任务是否执行成功,并且可以通过 Future 的 get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用 get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
我们以**AbstractExecutorService**接口中的一个 submit 方法为例子来看看源代码:
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
上面方法调用的 newTaskFor 方法返回了一个 FutureTask 对象。
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}
*4. 简述如何创建线程池?
方式一:通过构造方法实现

方式二:通过Executor框架的工具类Executors来实现我们可以创建三种类型的ThreadPoolExecutor:
- FixedThreadPool : 该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
- SingleThreadExecutor: 方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
- CachedThreadPool: 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
对应Executors工具类中的方法如图所示:
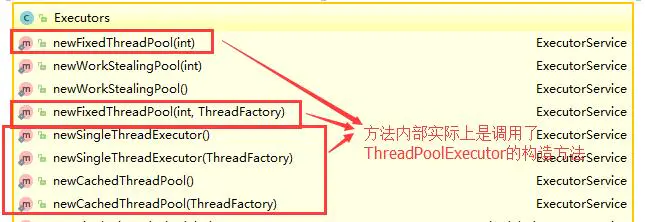
注意:《阿里巴巴Java开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
Executors 返回线程池对象的弊端如下:
- FixedThreadPool 和 SingleThreadExecutor : 允许请求的队列长度为 Integer.MAX_VALUE ,可能堆积大量的请求,从而导致OOM (out of memory)。
- CachedThreadPool 和 ScheduledThreadPool : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致OOM (out of memory)。
5. 简述如何使用Runnable+ThreadPoolExecutor实现一个简单线程池?
自定义一个MyRunnable 继承 Runnable
public class MyRunnable implements Runnable {
private String command;
public MyRunnable(String s) {
this.command = s;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " Start. Time = " + new Date());
processCommand();
System.out.println(Thread.currentThread().getName() + " End. Time = " + new Date());
}
private void processCommand() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public String toString() {
return this.command;
}
}
App.java
public class App
{
private static final int CORE_POOL_SIZE = 5;
private static final int MAX_POOL_SIZE = 10;
private static final int QUEUE_CAPACITY = 100;
private static final Long KEEP_ALIVE_TIME = 1L;
public static void main( String[] args ) {
//使用阿里巴巴推荐的创建线程池的方式
//通过ThreadPoolExecutor构造函数自定义参数创建
ThreadPoolExecutor executor = new ThreadPoolExecutor(
CORE_POOL_SIZE,
MAX_POOL_SIZE,
KEEP_ALIVE_TIME,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(QUEUE_CAPACITY),
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 0; i < 10; i++) {
//创建WorkerThread对象(WorkerThread类实现了Runnable 接口)
Runnable worker = new MyRunnable("" + i);
//执行Runnable
executor.execute(worker);
}
//终止线程池
executor.shutdown();
while (!executor.isTerminated()) {
}
System.out.println("Finished all threads");
}
}
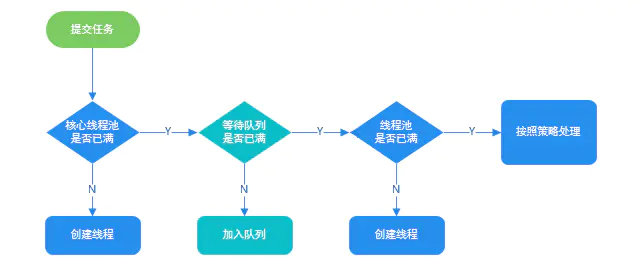
6. 简述线程池的内部执行原理?
为了搞懂线程池的原理,需要读源码 execute:
// 存放线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount)
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static int workerCountOf(int c) {
return c & CAPACITY;
}
private final BlockingQueue<Runnable> workQueue;
public void execute(Runnable command) {
// 如果任务为null,则抛出异常。
if (command == null)
throw new NullPointerException();
// ctl 中保存的线程池当前的一些状态信息
int c = ctl.get();
// 下面会涉及到3步操作
// 1.首先判断当前线程池中执行的任务数量是否小于 corePoolSize
// 如果小于的话,通过addWorker(command, true)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// 2.如果当前执行的任务数量大于等于 corePoolSize 的时候就会走到这里
// 通过 isRunning 方法判断线程池状态,线程池处于 RUNNING 状态并且队列可以加入任务,该任务才会被加入进去
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 再次获取线程池状态,如果线程池状态不是 RUNNING 状态就需要从任务队列中移除任务,并尝试判断线程是否全部执行完毕。同时执行拒绝策略。
if (!isRunning(recheck) && remove(command))
reject(command);
// 如果当前线程池为空就新创建一个线程并执行。
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//3. 通过addWorker(command, false)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。
//如果addWorker(command, false)执行失败,则通过reject()执行相应的拒绝策略的内容。
else if (!addWorker(command, false))
reject(command);
}
通过下图可以更好的对上面这 3 步:
7. 简述Atomic原子类?
Atomic 翻译成中文是原子的意思。在化学上,原子是构成一般物质的最小单位,在化学反应中是不可分割的。
在Java中,Atomic 是指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。
所以原子类就是具有原子/原子操作特征的类。
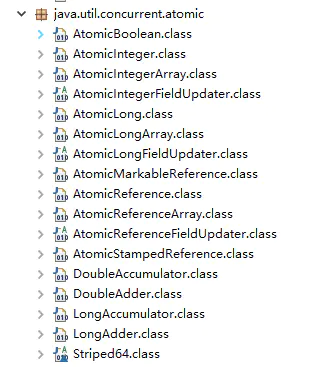
并发包 java.util.concurrent 的原子类都存放在java.util.concurrent.atomic下,如下图所示。
8. 简述常用的java.util.concurrent中原子类有哪些?
基本类型: 使用原子的方式更新基本类型
AtomicInteger:整形原子类
AtomicLong:长整型原子类
AtomicBoolean:布尔型原子类
数组类型:使用原子的方式更新数组里的某个元素
AtomicIntegerArray:整形数组原子类
AtomicLongArray:长整形数组原子类
AtomicReferenceArray:引用类型数组原子类
引用类型:
AtomicReference:引用类型原子类
AtomicStampedReference:原子更新引用类型里的字段原子类
AtomicMarkableReference :原子更新带有标记位的引用类型
对象的属性修改类型:
AtomicIntegerFieldUpdater:原子更新整形字段的更新器
AtomicLongFieldUpdater:原子更新长整形字段的更新器
AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
9. 举例如何使用AtomicInteger?
自定义一个AtomicIntegerWrapper类,并且使用
public class AtomicIntegerWrapper {
private AtomicInteger count = new AtomicInteger();
// 这里调用的是AtomicInteger的方法
// 因为是属于原子操作,AtomicInteger的方法都是基于CAS实现的
public void increment(){
count.incrementAndGet();
}
public void increment(int i){
count.addAndGet(i);
}
public int getCount() {
return count.get();
}
}
public class App
{
AtomicIntegerWrapper w = new AtomicIntegerWrapper();
System.out.println(w.getCount());
w.increment();
System.out.println(w.getCount());
w.increment(5);
System.out.println(w.getCount());
}
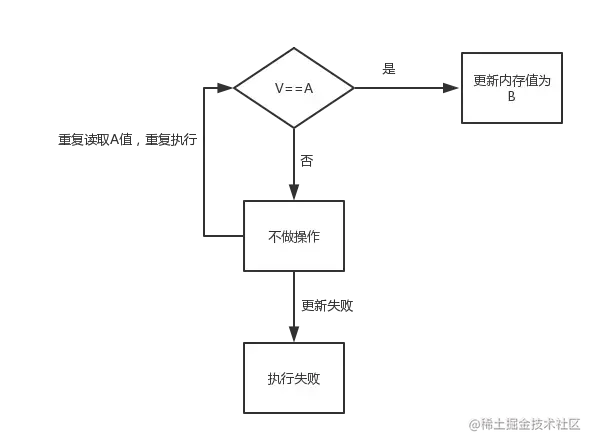
10.简述一下CAS与volatile
CAS(Compare And Swap)即比较并交换,CAS 是乐观锁技术,当多个线程尝试使用 CAS 同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。它包含三个参数:V 内存值,预期值 A,要修改的新值 B。当且仅当预期值 A 和内存值 V 相同时,将内存值 V 修改为 B,否则什么都不做。原理图如下所示:
volatile 是一种稍弱的同步机制,用来确保将变量的更新操作通知到其他线程。当把变量声明为 volatile 类型后,编译器与运行时都会注意到这个变量是共享的,因此不会将该变量上的操作与其他内存操作一起重排序。volatile 变量不会被缓存在寄存器或者对其他处理器不可见的地方,因此在读取 volatile 类型的变量时总返回最新写入的值。在访问 volatile 变量时不会执行加锁操作,因此也就不会使执行线程阻塞,因此 volatile 变量是一种比 sychronized 关键字更轻量级的同步机制。
11. 简述AtomicInteger类的原理?
AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
CAS的原理是拿期望的值和原本的一个值作比较,如果相同则更新成新的值。UnSafe 类的 objectFieldOffset() 方法是一个本地(native)方法,这个方法是用来拿到“原来的值”的内存地址,返回值是 valueOffset(地址偏移)。另外 value 是一个volatile变量,在内存中可见,因此 JVM 可以保证任何时刻任何线程总能拿到该变量的最新值。
// setup to use Unsafe.compareAndSwapInt for updates(更新操作时提供“比较并替换”的作用)
private static final Unsafe unsafe = Unsafe.getUnsafe();
private volatile int value;//内存值
// update:拿到的最新的值,expect:期望值
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
12. 简述什么是AQS?
AQS的全称为(AbstractQueuedSynchronizer),这个类在java.util.concurrent.locks包下面。
AQS是一个用来构建锁和同步器的框架,使用AQS能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的ReentrantLock,Semaphore,其他的诸如ReentrantReadWriteLock,SynchronousQueue,FutureTask等等皆是基于AQS的。当然,我们自己也能利用AQS非常轻松容易地构造出符合我们自己需求的同步器。
13. 简述AQS的原理?(公平锁)
AQS 原理:
AQS核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。
CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS是将每条请求共享资源的线程封装成一个CLH锁队列的一个结点(Node)来实现锁的分配。
看个AQS(AbstractQueuedSynchronizer)原理图:
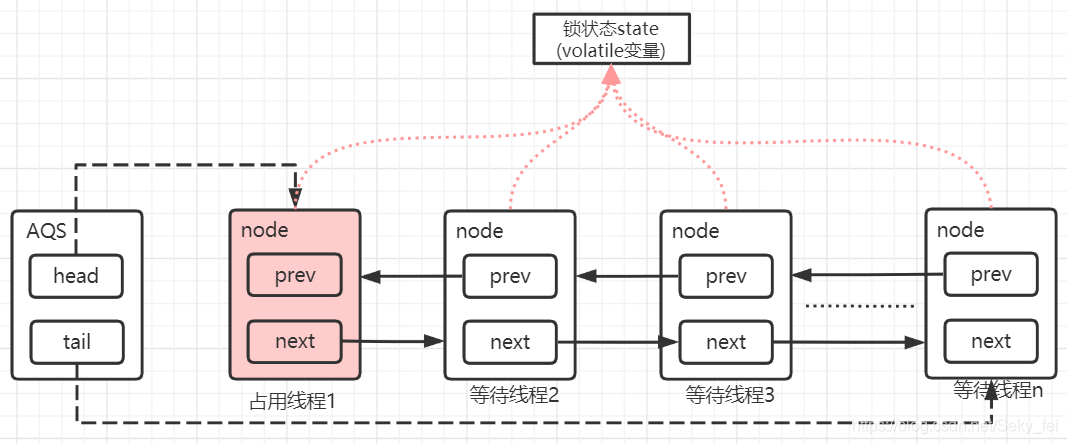
AQS使用一个int成员变量来表示同步状态,通过内置的FIFO队列来完成获取资源线程的排队工作。AQS使用CAS对该同步状态进行原子操作实现对其值的修改。
private volatile int state;//共享变量,使用volatile修饰保证线程可见性复制代码
状态信息通过protected类型的getState,setState,compareAndSetState进行操作
//返回同步状态的当前值
protected final int getState() {
return state;
}
// 设置同步状态的值
protected final void setState(int newState) {
state = newState;
}
//原子地(CAS操作)将同步状态值设置为给定值update如果当前同步状态的值等于expect(期望值)
protected final boolean compareAndSetState(int expect, int update) {
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
AQS 对资源的共享方式
AQS 定义两种资源共享方式
Exclusive(独占):只有一个线程能执行,如ReentrantLock。又可分为公平锁和非公平锁:
公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
非公平锁:当线程要获取锁时,无视队列顺序直接去抢锁,谁抢到就是谁的
Share(共享):多个线程可同时执行,如Semaphore/CountDownLatch。Semaphore、CountDownLatch、 CyclicBarrier、ReadWriteLock 我们都会在后面讲到。
ReentrantReadWriteLock 可以看成是组合式,因为ReentrantReadWriteLock也就是读写锁允许多个线程同时对某一资源进行读。
不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS已经在顶层实现好了。
AQS底层使用了模板方法模式:
同步器的设计是基于模板方法模式的,如果需要自定义同步器一般的方式是这样(模板方法模式很经典的一个应用):
使用者继承AbstractQueuedSynchronizer并重写指定的方法。(这些重写方法很简单,无非是对于共享资源state的获取和释放)
将AQS组合在自定义同步组件的实现中,并调用其模板方法,而这些模板方法会调用使用者重写的方法。
这和我们以往通过实现接口的方式有很大区别,这是模板方法模式很经典的一个运用。
AQS使用了模板方法模式,自定义同步器时需要重写下面几个AQS提供的模板方法:
isHeldExclusively()//该线程是否正在独占资源。只有用到condition才需要去实现它。
tryAcquire(int)//独占方式。尝试获取资源,成功则返回true,失败则返回false。
tryRelease(int)//独占方式。尝试释放资源,成功则返回true,失败则返回false。
tryAcquireShared(int)//共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true,失败则返回false。
默认情况下,每个方法都抛出 UnsupportedOperationException。 这些方法的实现必须是内部线程安全的,并且通常应该简短而不是阻塞。AQS类中的其他方法都是final ,所以无法被其他类使用,只有这几个方法可以被其他类使用。
以ReentrantLock为例,state初始化为0,表示未锁定状态。A线程lock()时,会调用tryAcquire()独占该锁并将state+1。此后,其他线程再tryAcquire()时就会失败,直到A线程unlock()到state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A线程自己是可以重复获取此锁的(state会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证state是能回到零态的。
再以CountDownLatch以例,任务分为N个子线程去执行,state也初始化为N(注意N要与线程个数一致)。这N个子线程是并行执行的,每个子线程执行完后countDown()一次,state会CAS(Compare and Swap)减1。等到所有子线程都执行完后(即state=0),会unpark()主调用线程,然后主调用线程就会从await()函数返回,继续后余动作。
一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现tryAcquire-tryRelease、tryAcquireShared-tryReleaseShared中的一种即可。但AQS也支持自定义同步器同时实现独占和共享两种方式,如ReentrantReadWriteLock。
14. 简述AQS有哪些组件?
Semaphore(信号量)-允许多个线程同时访问: synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量)可以指定多个线程同时访问某个资源。
CountDownLatch (倒计时器): CountDownLatch是一个同步工具类,用来协调多个线程之间的同步。这个工具通常用来控制线程等待,它可以让某一个线程等待直到倒计时结束,再开始执行。
CyclicBarrier(循环栅栏): CyclicBarrier 和 CountDownLatch 非常类似,它也可以实现线程间的技术等待,但是它的功能比 CountDownLatch 更加复杂和强大。主要应用场景和 CountDownLatch 类似。CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。CyclicBarrier默认的构造方法是 CyclicBarrier(int parties),其参数表示屏障拦截的线程数量,每个线程调用await()方法告诉 CyclicBarrier 我已经到达了屏障,然后当前线程被阻塞。

