线程池(Thread Pool)
线程池(Thread Pool)是一种基于池化思想管理线程的工具。线程过多会带来额外的开销,其中包括创建销毁线程的开销、调度线程的开销等等,同时也降低了计算机的整体性能。线程池维护多个线程,等待监督管理者分配可并发执行的任务。这种做法,一方面避免了处理任务时创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
一、Java中常用的四种线程池
在Java中使用线程池,可以用ThreadPoolExecutor的构造函数直接创建出线程池实例。不过,在Executors类中,为我们提供了常用线程池的创建方法。接下来我们就来了解常用的四种:newFixedThreadPool、newCachedThreadPool、newScheduledThreadPool、newSingleThreadExecutor
newFixedThreadPool
创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。创建方法:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
从构造方法可以看出,它创建了一个固定大小的线程池,每次提交一个任务就创建一个线程,直到线程达到线程池的最大值nThreads。线程池的大小一旦达到最大值后,再有新的任务提交时则放入**无界阻塞队列**中,等到有线程空闲时,再从队列中取出任务继续执行。
如何使用newFixedThreadPool?示例代码如下:
package test;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadPoolExecutorTest {
public static void main(String[] args) {
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
for (int i = 0; i < 12; i++) {
final int index = i;
fixedThreadPool.execute(new Runnable() {
public void run() {
try {
System.out.println(index);
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
}
线程池大小为3,每个任务输出index后sleep 3秒,所以每三秒打印3个数字。
定长线程池的大小最好根据系统资源进行设置。如Runtime.getRuntime().availableProcessors()
newCachedThreadPool
看一下这种线程池的创建方法:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
从构造方法可以看出,它创建了一个可缓存的线程池。当有新的任务提交时,有空闲线程则直接处理任务,没有空闲线程则创建新的线程处理任务,队列中不储存任务。线程池不对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。如果线程空闲时间超过了60秒就会被回收。
使用线程池可以带来一系列好处:
- 降低资源消耗:通过池化技术重复利用已创建的线程,降低线程创建和销毁造成的损耗。
- 提高响应速度:任务到达时,无需等待线程创建即可立即执行。
- 提高线程的可管理性:线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控。
- 提供更多更强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。比如延时定时线程池ScheduledThreadPoolExecutor,就允许任务延期执行或定期执行。
public class OneMoreStudy {
public static void main(String[] args) {
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 5; i++) {
final int index = i;
cachedThreadPool.execute(new Runnable() {
@Override
public void run() {
try {
SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
System.out.println("运行时间: " + sdf.format(new Date()) + " " + index);
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
cachedThreadPool.shutdown();
}
}
因为这种线程有新的任务提交,就会创建新的线程(线程池中没有空闲线程时),不需要等待,所以提交的5个任务的运行时间是一样的,运行结果如下:
运行时间: 08:45:18 2
运行时间: 08:45:18 1
运行时间: 08:45:18 3
运行时间: 08:45:18 4
运行时间: 08:45:18 0
newSingleThreadExecutor
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。看一下这种线程池的创建方法:
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
从构造方法可以看出,它创建了一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序执行。
public class OneMoreStudy {
public static void main(String[] args) {
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
for (int i = 0; i < 5; i++) {
final int index = i;
singleThreadExecutor.execute(new Runnable() {
@Override
public void run() {
try {
SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
System.out.println("运行时间: " + sdf.format(new Date()) + " " + index);
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}});
}
singleThreadExecutor.shutdown();
}
}
因为该线程池类似于单线程执行,所以先执行完前一个任务后,再顺序执行下一个任务,
运行结果如下:
运行时间: 08:54:17 0
运行时间: 08:54:19 1
运行时间: 08:54:21 2
运行时间: 08:54:23 3
运行时间: 08:54:25 4
既然类似于单线程执行,那么这种线程池还有存在的必要吗?这里的单线程执行指的是线程池内部,从线程池外的角度看,主线程在提交任务到线程池时并没有阻塞,仍然是异步的。
newScheduledThreadPool
这个方法创建了一个固定大小的线程池,支持定时及周期性任务执行。
首先看一下定时执行的例子:
public class OneMoreStudy {
public static void main(String[] args) {
final SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(3);
System.out.println("提交时间: " + sdf.format(new Date()));
scheduledThreadPool.schedule(new Runnable() {
@Override
public void run() {
System.out.println("运行时间: " + sdf.format(new Date()));
}
}, 3, TimeUnit.SECONDS);
scheduledThreadPool.shutdown();
}
}
使用该线程池的schedule方法,延迟3秒钟后执行任务,运行结果如下:
提交时间: 09:11:39
运行时间: 09:11:42
定期执行示例代码如下:
public class ThreadPoolExecutorTest {
public static void main(String[] args) {
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5);
scheduledThreadPool.scheduleAtFixedRate(new Runnable() {
public void run() {
System.out.println("delay 1 seconds, and excute every 3 seconds");
}
}, 1, 3, TimeUnit.SECONDS);
}
}
表示延迟1秒后每3秒执行一次。
二、线程池总体设计
Java中的线程池核心实现类是ThreadPoolExecutor。我们首先来看一下ThreadPoolExecutor的UML类图,了解下ThreadPoolExecutor的继承关系。
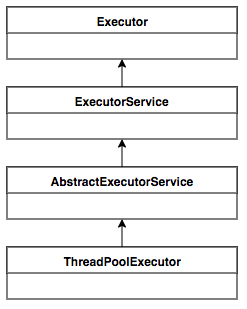
ThreadPoolExecutor实现的顶层接口是Executor,顶层接口Executor提供了一种思想:将任务提交和任务执行进行解耦。用户无需关注如何创建线程,如何调度线程来执行任务,用户只需提供Runnable对象,将任务的运行逻辑提交到执行器(Executor)中,由Executor框架完成线程的调配和任务的执行部分。
ExecutorService接口增加了一些能力:(1)扩充执行任务的能力,补充可以为一个或一批异步任务生成Future的方法;(2)提供了管控线程池的方法,比如停止线程池的运行。
AbstractExecutorService则是上层的抽象类,将执行任务的流程串联了起来,保证下层的实现只需关注一个执行任务的方法即可。
最下层的实现类ThreadPoolExecutor实现最复杂的运行部分,ThreadPoolExecutor将会一方面维护自身的生命周期,另一方面同时管理线程和任务,使两者良好的结合从而执行并行任务。
ThreadPoolExecutor运行机制
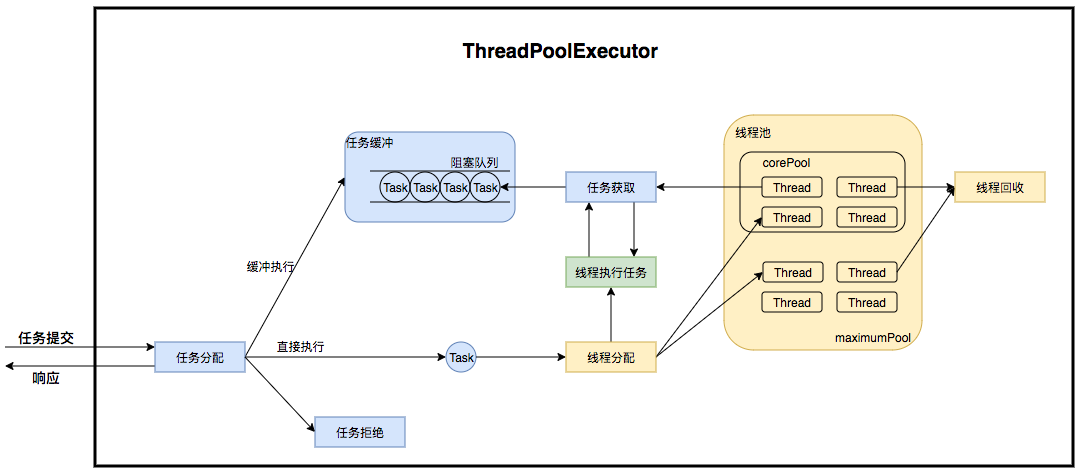
线程池在内部实际上构建了一个生产者消费者模型,将线程和任务两者解耦,并不直接关联,从而良好的缓冲任务,复用线程。线程池的运行主要分成两部分:任务管理、线程管理。任务管理部分充当生产者的角色,当任务提交后,线程池会判断该任务后续的流转:
(1)直接申请线程执行该任务;
(2)缓冲到队列中等待线程执行;
(3)拒绝该任务。
线程管理部分是消费者,它们被统一维护在线程池内,根据任务请求进行线程的分配,当线程执行完任务后则会继续获取新的任务去执行,最终当线程获取不到任务的时候,线程就会被回收。
接下来,我们会按照以下三个部分去详细讲解线程池运行机制:
- 线程池如何维护自身状态。
- 线程池如何管理任务。
- 线程池如何管理线程。
未完待耕~~~
参考博文
https://www.cnblogs.com/heihaozi/p/11741735.html
https://blog.csdn.net/u012426959/article/details/78795784
https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html

